前言
最近接了两个数据分析的项目,借着这个机会好好学习一下python数据分析这个方向,在这里将这两天使用的一些思路和踩过的坑总结出来。希望在后面的能够有所帮助。
首先python做数据分析几个常见库有
- NumPy:
- 描述: NumPy是一个强大的数值计算库,提供了支持大型多维数组和矩阵的高级数学函数。
- 使用: 用于数组操作、线性代数、随机数生成等。
- Pandas:
- 描述: Pandas是用于数据分析的重要库,提供了数据结构(如DataFrame和Series)和数据分析工具。
- 使用: 用于数据清洗、处理、分析和可视化。
- Matplotlib:
- 描述: Matplotlib是一个用于绘制二维图表的2D绘图库,支持各种图表类型。
- 使用: 用于生成静态、交互式和动态的数据可视化。
- Seaborn:
- 描述: Seaborn是建立在Matplotlib之上的统计图形库,简化了许多绘图任务。
- 使用: 用于创建漂亮的统计图,支持数据集可视化。
- Plotly:
- 描述: Plotly是一个交互式图表库,支持绘制各种图表,包括线图、散点图、热图等。
- 使用: 用于生成交互式和可分享的图表。
在做数据分析前一定要明确的点就是,我弄这个分析到底是要干嘛,我的项目目标是什么,我需要根据具已经有的数据弄哪些图表来辅助我完成分析。有了目标和方向才好去实施。那么在开始之前可以先去谷歌或者百度一下,别人有没有这方面的项目,别人的分析店在哪儿,数据集差异大不大,能借鉴多少,然后再来写自己的项目目标。
数据清洗

以上是一个不是很好的思路图。这个东西我觉得也没啥思路不思路的,按照自己的数据集一步一步的来就是了。
首先数据清洗,数据清洗,是数据可视化分析的一个重要前置条件,除了用python的pandas库外,wps的表格模块和excel都是很不错的工具,特别是对于一些对于python操作不熟练的人来说,使用可视化的excel或者wps是更好的选择。
我们根据数据集的内容不同故选择的清洗方向不一样,一般来说根据你的分析方向和原始数据集的内容来总分分析。我的思路是先检查空值,利用pandas库的info可以很好的查看数据完整性和数据类型。
file_path = '拉钩网招聘_数据分析_上海.csv'
df = pd.read_csv(file_path, encoding='GBK')
df.info()
然后是预处理,比如对于一些元素需要分列,对一些重复,多余的元素惊醒增删改之类的。然后对于一些缺失值,进行判断,能不能用,不能用是不是需要删除。删除指定列代码展示如下,同时我们会创立一个df.to_csv创立一个新的文件csv文件。
import pandas as pd
df = pd.read_csv('lipstick.csv')
columns_to_drop = ['image_src']
df = df.drop(columns=columns_to_drop, axis=1)
df.to_csv('new_lipstick1.csv', index=False)
而删除指定条件的行,就可以这样dropna()方法删除df中所有包含缺失值(NaN)的行。subset=['deal']参数指定了只考虑'deal'列中的缺失值,
import pandas as pd
df = pd.read_csv('new_lipstick1.csv')
df = df.dropna(subset=['deal'])
df.to_csv('new_lipstick2.csv', index=False)
对于数据集中的列名进行重命名我们可以这样操作
import pandas as pd
df = pd.read_csv('new_lipstick3.csv')
new_column_names = ['商品标题', '商品价格', '销售数据', '店铺名', '店铺地址']
df.columns = new_column_names
df.to_csv('new_lipstick4.csv', index=False)
等等太多了能够处理操作的了,这个根据自身实际需要来进行操作,对于一些实际需求可以遇到了在网上搜,或者选择使用ai来帮助完成一些要求
数据可视化分析
import matplotlib.pyplot as plt这应该是很多数据分析的第一个python语句,matplotlib有很多各种基础图表,同时使用也非常简单。本次使用的数据集里面的内容预览如下

数据清洗后的数据集预览如下
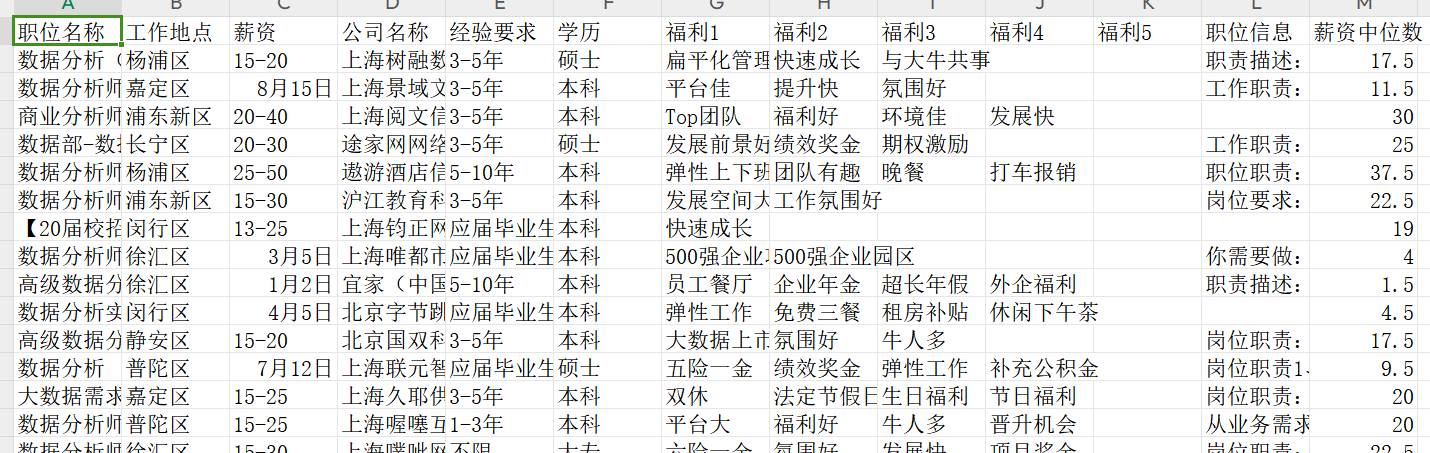
接下来我汇总我在数据分析时踩得坑和一些分析图像的制作方法。
箱线图
箱线图,也称为盒须图或盒式图,是一种用于展示数据分布的统计图表。它由一个箱子和两条胡须组成,箱子的上下边界分别代表数据的上四分位数和下四分位数,中间的横线代表中位数,而胡须则分别代表上四分位数和下四分位数之外的数据范围。
箱线图在数据统计中有以下几个主要的运用:
- 展示数据的分布情况:箱线图可以快速地展示数据的中心趋势、离散程度以及是否存在异常值。通过观察箱子的长度、宽度和胡须的长度,可以了解数据的集中程度、离散程度以及是否存在极端值。
- 比较不同数据集:箱线图可以用于比较多个数据集的分布情况。通过将多个箱线图并列显示,可以直观地比较不同数据集的中心位置、离散程度和范围,帮助分析它们之间的差异。
- 检测异常值:箱线图可以帮助识别数据中的异常值。如果某个数据点落在箱子之外,即胡须之外,那么它可能是一个异常值。通过观察箱线图,可以快速发现异常值,并对其进行进一步的分析或处理。
- 确定数据的偏态:箱线图可以提供关于数据偏态的信息。如果箱子的左边或右边较长,说明数据可能存在左偏或右偏;如果箱子比较扁平,说明数据可能接近正态分布。
- 用于数据摘要和报告:箱线图是一种简洁有效的方式,可以在数据摘要或报告中展示数据的分布情况。它可以提供有关数据集中趋势、离散程度和异常值的信息,帮助读者快速了解数据的特征。

首先第一个容易踩坑的点就是编码格式,很多时候表示在我们不太清楚自己的数据集的编码格式那么直接读的话会产生会这样的报错
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xc3 in position 4: invalid continuation byte
表示在尝试使用 utf-8 编解码时发生了解码错误。我推测可能是很多数据都是gbk编码的而这个函数默认以utf—8打开会出问题,加一个encoding='gbk'一般就能打开。然后就是字体,很多时候包括饼图,词云等等都会出现中文乱码,比如那种框框的情况我们这个时候只需要在读取后加一个
font = FontProperties(fname=r"C:\Windows\Fonts\msyh.ttc", size=12)
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei'] # 设置全局字体为微软雅黑
一般来说字体都是在那个目录下,我遇到的所有图像字体问题都能通过这个解决
#经验要求与薪资的关系箱线图
import pandas as pd
import matplotlib.pyplot as plt
from matplotlib.font_manager import FontProperties
# 读取数据时指定编码为 'gbk'
df = pd.read_csv('new_数据分析_上海_3.csv', encoding='gbk')
# 设置字体为微软雅黑
font = FontProperties(fname=r"C:\Windows\Fonts\msyh.ttc", size=12)
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei'] # 设置全局字体为微软雅黑
plt.figure(figsize=(10, 6))
df.boxplot(column='薪资中位数', by='经验要求', showfliers=False)
plt.title('数据分析师经验要求与薪资数关系箱线图', fontproperties=font)
plt.suptitle('')
plt.xlabel('经验要求(年)', fontproperties=font)
plt.ylabel('薪资(k)', fontproperties=font)
plt.show()
词云
这里使用合并福利待遇信息来制作词云,虽然词云的逻辑是提取关键词,比如这儿 扁平化管理,快速成长,与大牛共事,他是能识别这几个关键词的,但是他不能识别’,‘特别是以gbk编码的时候。
一般都会报错
UnicodeDecodeError: 'gbk' codec can't decode byte 0xaa in position 28: illegal multibyte sequence
那么我们就可以在数据清洗的时候把他分开,在这儿在合并
import pandas as pd
from wordcloud import WordCloud
import matplotlib.pyplot as plt
from matplotlib.font_manager import FontProperties
# 读取数据时指定编码方式为'gbk'
df = pd.read_csv('new_数据分析_上海_3.csv', encoding='gbk')
# 合并福利待遇信息
welfare_columns = ['福利1', '福利2', '福利3', '福利4', '福利5']
welfare_text = ' '.join(df[welfare_columns].fillna('').values.flatten())
# 提取职位名称信息
#job_titles = ' '.join(df['职位名称'].fillna('').values)
# 设置字体为微软雅黑
font = FontProperties(fname=r"C:\Windows\Fonts\msyh.ttc", size=12)
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei']
# # 生成词云
wordcloud = WordCloud(width=800, height=400, background_color='white', font_path=r"C:\Windows\Fonts\msyh.ttc").generate(welfare_text)#替换这儿的welfare_txet)就可以了
# 显示词云图
plt.figure(figsize=(10, 5))
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis('off')
plt.title('公司福利待遇词云', fontsize=16)
# 显示图形
plt.show()
热力图
热力图这个东西看着非常炫酷,特别是有些数据集有办公地点的行政区名就可以尝试用热力图。效果如下:
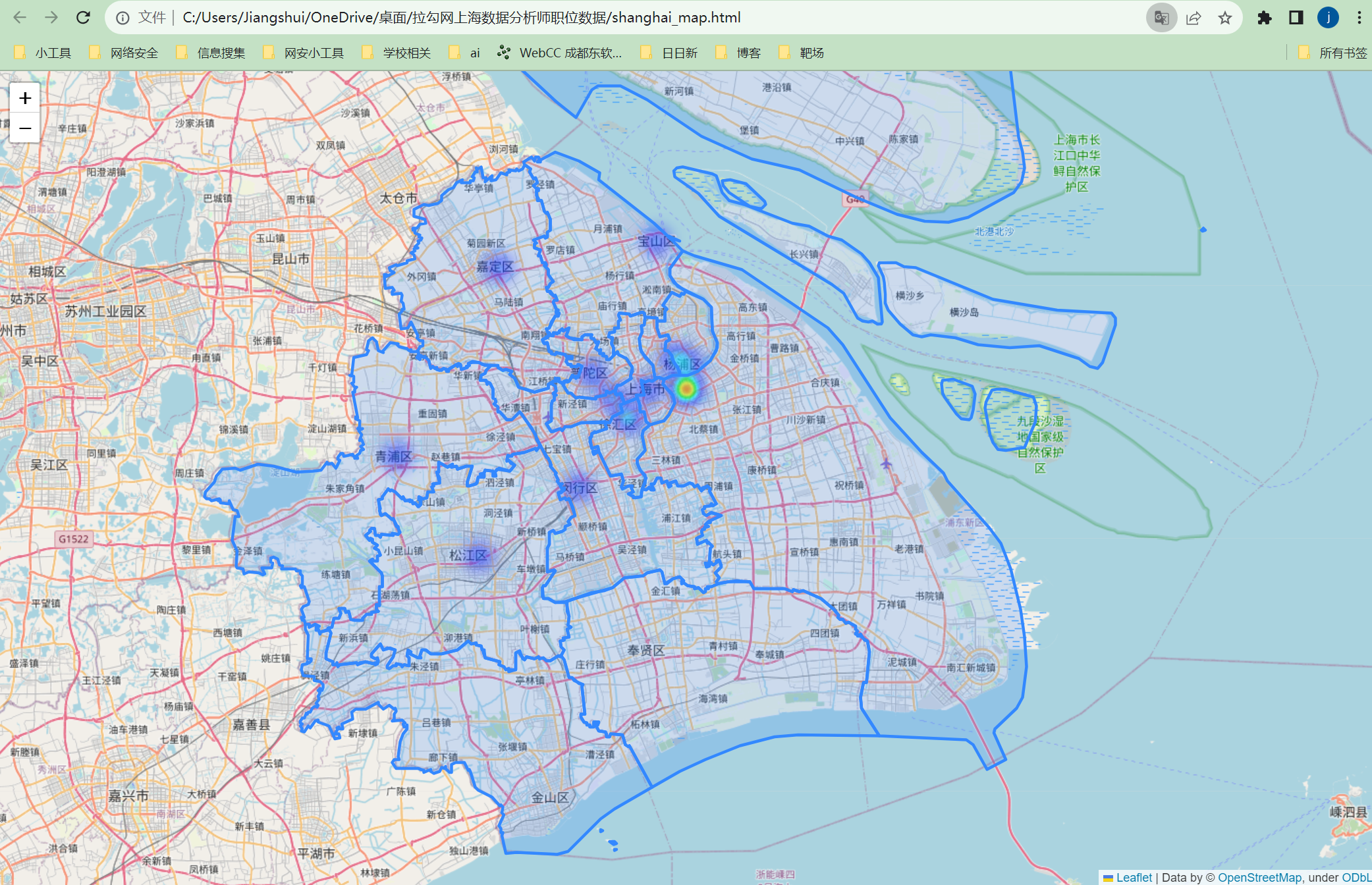
那么制作热力图首先得知道得治到目标点的地理边界坐标信息,我这里用的是geojson文件,这个可以在网上直接搜索某地geojson文件下载就有。我用的是
https://geojson.hxkj.vip/
那么接下来还需要找到各个点的中心坐标,来替换,这里我选择的 是直接问ai,让它帮我汇总结果,然后直接套进去区就行
x 1import pandas as pd2import folium3from folium.plugins import HeatMap4import json5# 读取数据时指定编码方式为'gbk'6df = pd.read_csv('new_数据分析_上海_3.csv', encoding='gbk')7# 读取上海市各区的地理边界数据(GeoJSON 文件)8geojson_file = 'shanghaimap.geoJson'9shanghai_geojson = json.load(open(geojson_file, encoding='utf-8-sig'))10# 创建 folium 地图,并添加上海市各区的地理边界11shanghai_map = folium.Map(location=[31.2304, 121.4737], zoom_start=11)12folium.GeoJson(shanghai_geojson).add_to(shanghai_map)13# 设置区域坐标,使用中心坐标14coordinates = {15 '浦东新区': [31.2304, 121.5265],16 '徐汇区': [31.1946, 121.4460],17 '长宁区': [31.2208, 121.4233],18 '静安区': [31.2289, 121.4737],19 '普陀区': [31.2491, 121.3945],20 '虹口区': [31.2679, 121.5077],21 '杨浦区': [31.2623, 121.5293],22 '闵行区': [31.1134, 121.3751],23 '宝山区': [31.4053, 121.4847],24 '嘉定区': [31.3749, 121.2658],25 '金山区': [30.7443, 121.1657],26 '松江区': [31.0317, 121.2378],27 '青浦区': [31.1508, 121.1246],28 '奉贤区': [30.9157, 121.4787],29 '崇明区': [31.6239, 121.3977]30}31df['Coordinates'] = df['工作地点'].map(coordinates)32heat_data = df.dropna(subset=['Coordinates'])['Coordinates'].values.tolist()33HeatMap(heat_data, radius=15).add_to(shanghai_map)34table_html = df['工作地点'].value_counts().reset_index().to_html()35folium.Map(location=[0, 0], zoom_start=1).get_root().html.add_child(folium.Element(table_html))36# 保存地图为 HTML 文件37shanghai_map.save('shanghai_map.html')38
后面还会将学到的内容和踩得坑持续更新到这上面的。后续又接了两次分析任务,任务要求是使用jupyter,因为前期不太了解就随便下载了一个jupyterlite我现在都不知道这是一个什么软件。然后就是各种各样的问题,开始打开不了指定目录文件,网上去搜教程,折腾了快半小时,还是不行,只能又去移动目录,后续又有字体问题按照网上的教程,指定本地目录修改库函数的 字体库等等,看了好几篇教程都是不能解决。我就恼了,开始换软件,去网上找正常的软件,后续使用了anaconda下的jupyter notebook,那叫一个舒服,不必担心字体,文件读取也没有问题。后面的项目就开始在jupyter上写的,算是开发了一个新的软件吧,使用下来感觉不错,交互体验也不错。
购车数量前十的车型购车数量分布和购车时间趋势
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from matplotlib.font_manager import FontProperties
#数据在df中
colors = ["#191970", "#4169E1", "#B0C4DE", "#87CEFA", "#87CEEB", "#ADD8E6"]
# 选择购车数量前十的车型
top_car_types = df['购买车型'].value_counts().nlargest(10).index
df_top10 = df[df['购买车型'].isin(top_car_types)]
df_top10['购车时间'] = pd.to_datetime(df_top10['购车时间'], format='%Y年%m月')
df_top10['月份'] = df_top10['购车时间'].dt.month
plt.figure(figsize=(12, 12))
df_top10.groupby(['月份', '购买车型']).size().unstack().plot(kind='line', marker='o', color=colors)
plt.title('购车数量前十的车型购车数量分布和购车时间趋势')
plt.xlabel('购车时间(月份)')
plt.ylabel('购车数量')
plt.legend(title='车型', bbox_to_anchor=(1, 1))
plt.xticks(df_top10['月份'].unique())
plt.show()
关于图像很多都是都是可以利用ai制作,他们显然对这方面有更高的能力。相较于我们效率更高。我们要做的就是合理的引导它,让他一步步的靠近我们的正确想法。
总结
本次短暂的兼职也让我了解到了更多的资源认识到了很多新方向。
kaggle数据分析的社区有很多不错的数据集和牛人的分析过程,都是用ipynb格式的。
在问很不错的的一个综合类ai项目,国内直接访问,ai类型多,免费功能也多
一个开源的数据清洗工具pygwalker